redis的基本知识
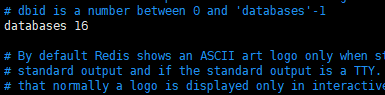
1.redis默认有16个数据库,
可以vim进它的配置文件查看: vim sconfig/redis.conf

默认使用的是第0个,可以使用select进行切换数据库!
切换到第三个数据库:
127.0.0.1:6379> select 3 #切换到第三个数据库
OK
127.0.0.1:6379[3]>
127.0.0.1:6379[3]> dbsize #查看数据库大小
(integer) 0
127.0.0.1:6379[3]> set name sovzn
OK
127.0.0.1:6379[3]> dbsize
(integer) 1
清空当前数据库:flushdb
清空所有数据库(不管在第几个数据库执行):flushall
2.redis是单线程的
因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了。
详细原因:
(1)不需要各种锁的性能消耗
Redis的数据结构并不全是简单的Key-Value,还有list,hash等复杂的结构,这些结构有可能会进行很细粒度的操作,比如在很长的列表后面添加一个元素,在hash当中添加或者删除
一个对象。这些操作可能就需要加非常多的锁,导致的结果是同步开销大大增加。
总之,在单线程的情况下,就不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗。
(2)单线程多进程集群方案
单线程的威力实际上非常强大,每核心效率也非常高,多线程自然是可以比单线程有更高的性能上限,但是在今天的计算环境中,即使是单机多线程的上限也往往不能满足需要了,需要进一步摸索的是多服务器集群化的方案,这些方案中多线程的技术照样是用不上的。
所以单线程、多进程的集群不失为一个时髦的解决方案。
(3)CPU消耗
采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU。
但是如果CPU成为Redis瓶颈,或者不想让服务器其他CUP核闲置,那怎么办?
可以考虑多起几个Redis进程,Redis是key-value数据库,不是关系数据库,数据之间没有约束。只要客户端分清哪些key放在哪个Redis进程上就可以了。
3.为什么redis是单线程还这么快?
误区1:高性能的服务器一定是多线程
误区2:多线程(CPU上下文会切换)一定比单线程效率高
- redis是基于内存的,内存的读写速度非常快;
- redis是单线程的,省去了很多上下文切换线程的时间;
- redis使用多路复用技术,可以处理并发的连接。非阻塞IO 内部实现采用epoll,采用了epoll+自己实现的简单的事件框架。epoll中的读、写、关闭、连接都转化成了事件,然后利用epoll的多路复用特性,绝不在io上浪费一点时间。
redis-key
127.0.0.1:6379> keys * #查看所有的key
(empty array)
127.0.0.1:6379> set name sovzn
OK
127.0.0.1:6379> set age 1
OK
127.0.0.1:6379> keys *
1) "name"
2) "age"
127.0.0.1:6379> exists name #查看当前key是否存在
(integer) 1
127.0.0.1:6379> exists name1
(integer) 0
127.0.0.1:6379> move name 1 #移除当前的key ,“1”代表当前数据库
(integer) 1
127.0.0.1:6379> keys *
1) "age"
127.0.0.1:6379> set name1 sovzn
OK
127.0.0.1:6379> get name1
"sovzn"
127.0.0.1:6379> expire name1 10 # expire:设置key的过期时间,单位是秒
(integer) 1
127.0.0.1:6379> ttl name1 #ttl: 查看当前key的剩余时间
(integer) 5
127.0.0.1:6379> ttl name1
(integer) -2
127.0.0.1:6379> type age # 查看当前key的类型
string



- Post link: http://sovzn.github.io/2021/02/01/Redis%E7%9A%84%E5%9F%BA%E6%9C%AC%E7%9F%A5%E8%AF%86/
- Copyright Notice: All articles in this blog are licensed under unless otherwise stated.
若没有本文 Issue,您可以使用 Comment 模版新建。
GitHub Issues