JVM内存

我们java底层源码中会发现很多带native的方法,凡是带了native关键字的,如:private native void start0( );说明java的作用范围打不到了,会去调用底层C、C++语言的库!
对于这种,首先会进入本地方法栈,调用本地方法接口(JNI),通过本地方法接口来获取本地方法库中的方法
本地方法栈
Native Method Stack :登记native方法,在执行引擎(Execution Engine)执行的时候加载 Native Libraies(本地库)
程序计数器
也称为 PC寄存器:Program Counter Register
每一个线程都有一个程序计数器,是线程私有的,就是一个指针,指向当前线程正在执行的字节码的地址和行号。
程序执行的最小单位是线程,线程A和线程B对CPU的时间片资源是抢占式争夺,任何一个线程在使用CPU的时候,其他线程就被挂起,无法使用CPU。
当一个优先级更高的线程要抢占当前CPU资源时,当前线程可能未必执行完毕就被挂起,此时就需要保存现场信息,以便当前线程再次抢到CPU资源后继续执行。程序计数器的作用就是保存现场信息,每个线程都有自己的程序计数器。
方法区
Method Area:方法区是被所有线程共享的,所有字段和方法字节码,以及一些特殊方法,如:构造方法,接口代码也在此定义,简单地说,所有定义的方法的信息保存在该区域,此区域属于共享区间
静态变量(类变量),常量,类信息(构造方法,接口定义),运行时的常量池都存在于方法区中,但是实例变量存在于堆内存中,与方法区无关。
栈
栈:是一种数据结构, 栈是运行时的单位 ,先进后出,后进先出。
队列:先进先出(FIFO,First Input First Output),后进后出。
栈内存主管程序的运行,生命周期和线程同步,线程结束,栈内存也就释放了,程序正在执行的方法一定在栈的顶部。对于栈来说不存在垃圾回收问题。
描述的是 Java 方法执行的内存模型:每个方法在执行时都会创建一个栈帧(Stack Frame)用于存储局部变量表(形参也是局部变量)、操作数栈、动态链接、方法出口等信息。每一个方法从调用直至执行结束,就对应着一个栈帧从虚拟机栈中入栈到出栈的过程。
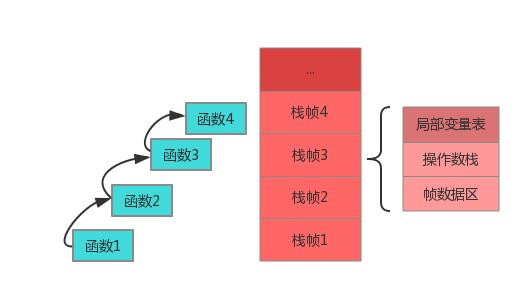
局部变量表:存放了编译期可知的各种基本类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference 类型)和 returnAddress 类型(指向了一条字节码指令的地址)
三种JVM(了解)
- Sun公司的Hotspot:是目前使用最广泛的java虚拟机
- BEA公司的JRockit: Oracle JRockit (原来的 Bea JRockit)JRockit JVM是世界上最快的JVM。适合财务前端办公、军事指挥与控制和电信网络的需要
- IBM公司的J9VM 是一个高性能的企业级 Java 虚拟机
可以通过java -version查看虚拟机版本:
C:\Users\16891>java -version
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode) #HotSpot
C:\Users\16891>堆
heap: 堆是存储时的单位,对于绝大多数应用来说,这块区域是 JVM 所管理的内存中最大的一块。线程共享,主要是存放对象实例和数组。 在堆中保存着我们所有引用类型(栈中)的真实对象;
堆中可分为三个区域:
新生区 young
老年区 old
永久区 permanent


新生区:
新生成的对象优先存放在新生区中,新生区对象朝生夕死,存活率很低,在新生区中,常规应用进行一次垃圾收集一般可以回收70% ~ 95% 的空间,回收效率很高。
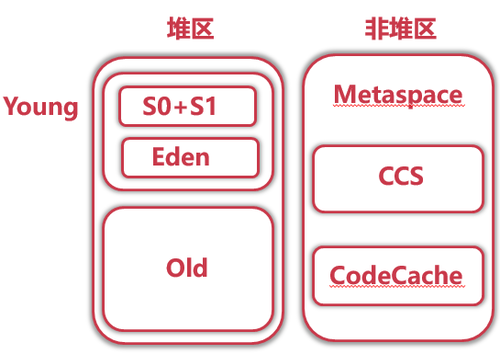
HotSpot将新生区划分为三块,一块较大的Eden(伊甸)空间和两块较小的Survivor(幸存者)空间(幸存区中谁空谁是to),默认比例为8:1:1。划分的目的是因为HotSpot采用复制算法来回收新生区,设置这个比例是为了充分利用内存空间,减少浪费。新生成的对象在Eden区分配(大对象除外,大对象直接进入老年区),当Eden区没有足够的空间进行分配时,虚拟机将发起一次Minor GC。
GC(复制算法)开始时,对象只会存在于Eden区和From Survivor区,To Survivor区是空的(作为保留区域)。GC进行时,Eden区中所有存活的对象都会被复制到To Survivor区,而在From Survivor区中,仍存活的对象会根据它们的年龄值决定去向,年龄值达到年龄阀值(默认为15,新生区中的对象每熬过一轮垃圾回收,年龄值就加1,GC分代年龄存储在对象的header中)的对象会被移到老年代中,没有达到阀值的对象会被复制到To Survivor区。接着清空Eden区和From Survivor区,新生区中存活的对象都在To Survivor区。接着, From Survivor区和To Survivor区会交换它们的角色,也就是新的To Survivor区就是上次GC清空的From Survivor区,新的From Survivor区就是上次GC的To Survivor区,总之,不管怎样都会保证To Survivor区在一轮GC后是空的。GC时当To Survivor区没有足够的空间存放上一次新生代收集下来的存活对象时,需要依赖老年代进行分配担保,将这些对象存放在老年区中。
老年区:
在新生区中经历了多次(具体看虚拟机配置的阀值)GC后仍然存活下来的对象会进入老年区中。老年代中的对象生命周期较长,存活率比较高,在老年区中进行GC的频率相对而言较低,而且回收的速度也比较慢。
永久区:
永久区是常驻内存的,用来存放jdk自身携带的class对选哪个,对这一区域而言,Java虚拟机规范指出可以不进行垃圾收集,一般而言不会进行垃圾回收。 在JDK1.2 ~ JDK6的实现中,HotSpot使用永久区实现方法区,从JDK7开始Oracle、HotSpot开始移除永久代(永久区),JDK7中符号表被移动到Native Heap中,字符串常量和类引用被移动到Java Heap中。在JDK8中,字符串常量依然在堆中,“永久代”完全被元空间(Meatspace)所取代。
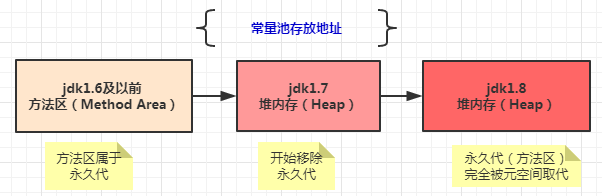
注:jdk1.8后没有永久区,jdk1.8以前常量池就存储在永久区
hotspot jdk8中移除了永久带以后的内存结构 :
OOM
在Java虚拟机规范的描述中,除了程序计数器外,虚拟机内存的其他几个运行时区域都有发生OutOfMemoryError(下文称OOM)异常的可能。
造成OOM的原因
Java堆溢出:heap
Java堆内存主要用来存放运行过程中所以的对象,该区域OOM异常一般会有如下错误信息;
java.lang.OutofMemoryError:Java heap space
此类错误一般通过Eclipse Memory Analyzer分析OOM时dump的内存快照就能分析出来,到底是由于程序原因导致的内存泄露,还是由于没有估计好JVM内存的大小而导致的内存溢出。
另外,Java堆常用的JVM参数:
- Xms:初始堆大小,默认值为物理内存的1/64(<1GB),默认(MinHeapFreeRatio参数可以调整)空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制.
- -Xmx:最大堆大小,默认值为物理内存的1/4(<1GB),默认(MaxHeapFreeRatio参数可以调整)空余堆内存大于70%时,JVM会减少堆直到 -Xms的最小限制
- -Xmn:年轻代大小(1.4or lator),此处的大小是(eden + 2 survivor space),与jmap -heap中显示的New gen是不同的。
栈溢出:stack
在java虚拟机规范中,虚拟机栈和本地方法栈都肯定会出现溢出现象。
栈用来存储线程的局部变量表、操作数栈、动态链接、方法出口等信息。如果请求栈的深度不足时抛出的错误会包含类似下面的信息:
java.lang.StackOverflowError
另外,由于每个线程占的内存大概为1M,因此线程的创建也需要内存空间。操作系统可用内存-Xmx-MaxPermSize即是栈可用的内存,如果申请创建的线程比较多超过剩余内存的时候,也会抛出如下类似错误:
java.lang.OutofMemoryError: unable to create new native thread
相关的JVM参数有:
运行时常量溢出 constant
运行时常量保存在方法区,存放的主要是编译器生成的各种字面量和符号引用,但是运行期间也可能将新的常量放入池中,比如String类的intern方法。
如果该区域OOM,错误结果会包含类似下面的信息:
java.lang.OutofMemoryError: PermGen space
相关的JVM参数有:
XX:PermSize:设置持久代(perm gen)初始值,默认值为物理内存的1/64
XX:MaxPermSize:设置持久代最大值,默认为物理内存的1/4
方法区溢出 directMemory
方法区主要存储被虚拟机加载的类信息,如类名、访问修饰符、常量池、字段描述、方法描述等。理论上在JVM启动后该区域大小应该比较稳定,但是目前很多框架,比如Spring和Hibernate等在运行过程中都会动态生成类,因此也存在OOM的风险。
相关的JVM参数可以参考运行时常量。
JProfiler
JProfiler 是由 ej-technologies 公司开发的一款 Java 应用性能诊断工具,可以使用它来分析产生OOM的原因,与其相似的工具还有MAT等。
它聚焦于四个重要主题上。
- 方法调用 - 对方法调用的分析可以帮助您了解应用程序正在做什么,并找到提高其性能的方法。
- 内存分配 - 通过分析堆上对象、引用链和垃圾收集能帮您修复内存泄漏问题,优化内存使用。
- 线程和锁 - JProfiler 提供多种针对线程和锁的分析视图助您发现多线程问题。
- 高级子系统 - 许多性能问题都发生在更高的语义级别上。例如,对于JDBC调用,您可能希望找出执行最慢的 SQL 语句。JProfiler 支持对这些子系统进行集成分析。
官网:https://www.ej-technologies.com/products/jprofiler/overview.html
jprofiler11(含注册机): 链接:https://pan.baidu.com/s/1HlRG8NFnOBXGWl05TwJSuA 提取码:w4lb
Idea集成JProfile:
- 在安装jprofile过程中选择软件时选择idea;
- 在idea中下载安装插件jprofiler,打开settings,查看在Tools下有没有jprofiler,如果没有,清除缓存后重启idea(file→ Invalidate Caches/Restart → invalidate and restart)。
- 设置jprofiler的路径jprofiler executable:选择jprofiler 目录下bin下的exe文件,如:E:\jprofiler11\bin\jprofiler.exe
- 完成上述操作,在idea程序中点击jprofile插件图标就会跳转到刚安装的jprofile软件中。
GC :垃圾回收
垃圾回收只存在于方法区和堆中
GC有两种类型:
- 轻GC(普通GC)
- 重GC(全局GC)
GC的算法
复制算法
新生代(新生区)主要使用复制算法。算法原理如上新生代中所描述。
## 复制算法
GC(**复制算法**)开始时,对象只会存在于Eden区和From Survivor区,To Survivor区是空的(作为保留区域)。GC进行时,Eden区中所有存活的对象都会被复制到To Survivor区,而在From Survivor区中,仍存活的对象会根据它们的年龄值决定去向,年龄值达到年龄阀值(默认为15,新生区中的对象每熬过一轮垃圾回收,年龄值就加1,GC分代年龄存储在对象的header中)的对象会被移到老年代中,没有达到阀值的对象会被复制到To Survivor区。接着清空Eden区和From Survivor区,新生区中存活的对象都在To Survivor区。接着, From Survivor区和To Survivor区会交换它们的角色,也就是新的To Survivor区就是上次GC清空的From Survivor区,新的From Survivor区就是上次GC的To Survivor区,总之,不管怎样都会保证To Survivor区在一轮GC后是空的。GC时当To Survivor区没有足够的空间存放上一次新生代收集下来的存活对象时,需要依赖老年代进行分配担保,将这些对象存放在老年区中。优点:
- 优秀的吞吐量
- 不会发生碎片化
- 与缓存兼容
- 可实现高速分配:复制算法不用使用空闲链表。这是因为分块是连续的内存空间,因此,调用这个分块的大小,只需要这个分块大小不小于所申请的大小,移动指针进行分配即可。
缺点:
- 堆的使用率低
标记-清除算法
该算法分为标记和清除两个阶段。标记就是把所有活动对象都做上标记的阶段;清除就是将没有做上标记的对象进行回收的阶段。如下图所示。

优点:
不需要额外的空间
缺点:
分配速度:需要进行两次扫描, 分块不是连续的,因此每次分块都要遍历空闲链表,找到足够大的分块,从而造成时间的浪费。
会发生碎片化: 如上图所示,在回收的过程中会产生被细化的分块,到后面,即使堆中分块的总大小够用,但是却因为分块太小而不能执行分配,标记-压缩算法解决了这一缺点。
标记-压缩算法
标记-压缩算法与标记-清理算法类似,只是后续步骤是让所有存活的对象移动到一端,然后直接清除掉端边界以外的内存,可以防止内存碎片化。

优缺点:
该算法可以有效的利用堆,但是压缩需要花比较多的时间成本。
引用计数法
所谓的引用计数法就是给每个对象一个引用计数器,每当有一个地方引用它时,计数器就会加 1;当引用失效时,计数器的值就会减 1;任何时刻计数器的值为0的对象就是不可能再被使用的。
这个引用计数法是没有被Java所使用的,但是python有使用到它。而且最原始的引用计数法没有用到GC Roots。
GC算法总结
内存效率:复制算法 > 标记-清除法 > 标记-压缩算法(时间复杂度)
内存整齐度:复制算法= 标记-压缩算法 > 标记-清除算法
内存利用率:标记-压缩算法 = 标记-清除算法 > 复制算法
GC也称为分代收集算法
新生代:存活率低,使用复制算法
老年代:区域大,存活率高,使用标记-清除和标记-压缩混合算法



- Post link: http://sovzn.github.io/2021/02/24/JVM-%E5%86%85%E5%AD%98%EF%BC%88%E8%BF%90%E8%A1%8C%E6%97%B6%E6%95%B0%E6%8D%AE%E5%8C%BA%EF%BC%89OOM%E4%BB%A5%E5%8F%8AGC/
- Copyright Notice: All articles in this blog are licensed under unless otherwise stated.
若没有本文 Issue,您可以使用 Comment 模版新建。
GitHub Issues