MQ的应用场景
异步处理
场景说明:用户注册后,需要发注册邮件和注册短信,传统的做法有两种 1.串行的方式 2.并行的方式
串行方式:将注册信息写入数据库后,发送注册邮件,再发送注册短信,以上三个任务全部完成后才返回给客户端。 这有一个问题是,邮件,短信并不是必须的,它只是一个通知,而这种做法让客户端等待没有必要等待的东西.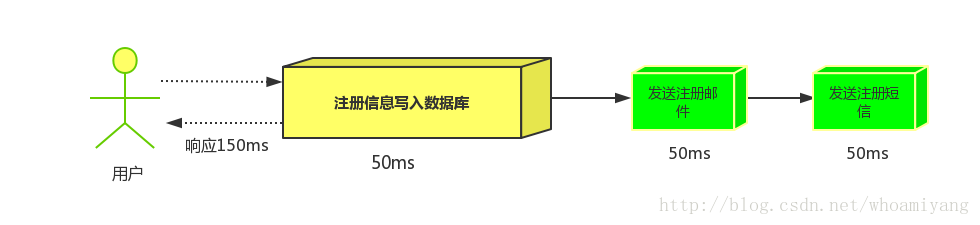
并行方式:将注册信息写入数据库后,发送邮件的同时,发送短信,以上三个任务完成后,返回给客户端,并行的方式能提高处理的时间。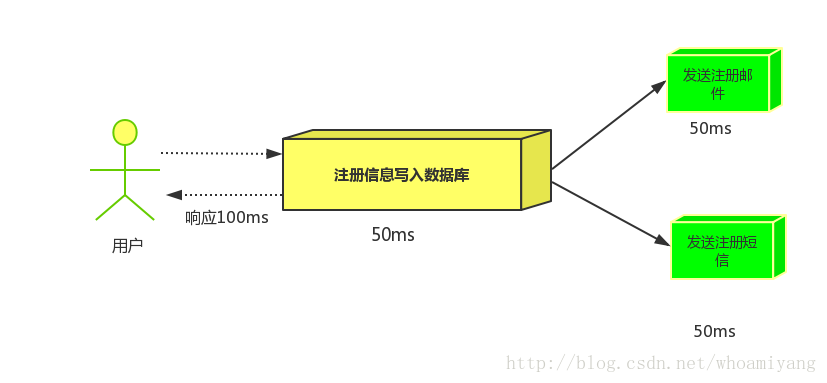
消息队列:假设三个业务节点分别使用50ms,串行方式使用时间150ms,并行使用时间100ms。虽然并行已经提高的处理时间,但是,前面说过,邮件和短信对我正常的使用网站没有任何影响,客户端没有必要等着其发送完成才显示注册成功,应该是写入数据库后就返回.消息队列: 引入消息队列后,把发送邮件,短信不是必须的业务逻辑异步处理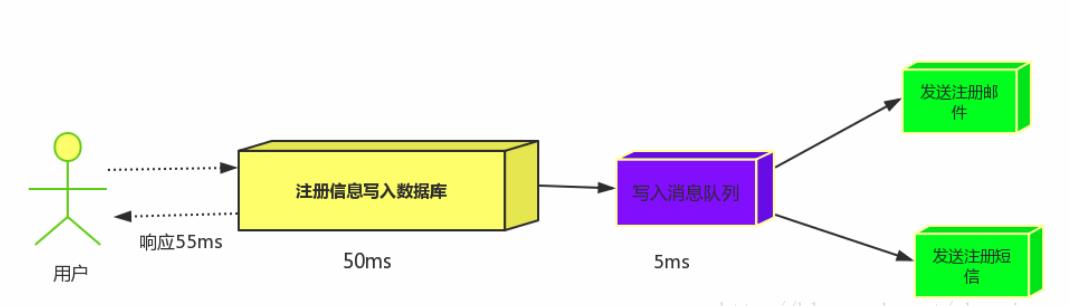
由此可以看出,引入消息队列后,用户的响应时间就等于写入数据库的时间+写入消息队列的时间(可以忽略不计),引入消息队列后处理后,响应时间是串行的3倍,是并行的2倍。
应用解耦
场景:双11是购物狂节,用户下单后,订单系统需要通知库存系统,传统的做法就是订单系统调用库存系统的接口.
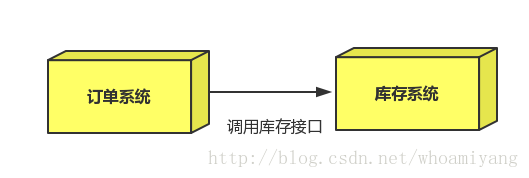
这种做法有一个缺点:
当库存系统出现故障时,订单就会失败。 订单系统和库存系统高耦合. 引入消息队列
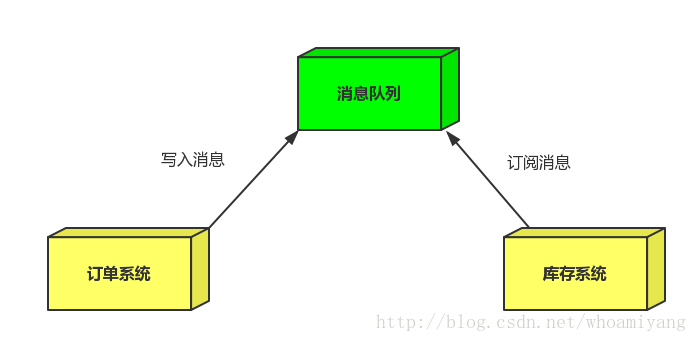
订单系统:用户下单后,订单系统完成持久化处理,将消息写入消息队列,返回用户订单下单成功。库存系统:订阅下单的消息,获取下单消息,进行库操作。 就算库存系统出现故障,消息队列也能保证消息的可靠投递,不会导致消息丢失.
流量削峰
场景: 秒杀活动,一般会因为流量过大,导致应用挂掉,为了解决这个问题,一般在应用前端加入消息队列。
作用:
1.可以控制活动人数,超过此一定阀值的订单直接丢弃(我为什么秒杀一次都没有成功过呢^^)
2.可以缓解短时间的高流量压垮应用(应用程序按自己的最大处理能力获取订单)
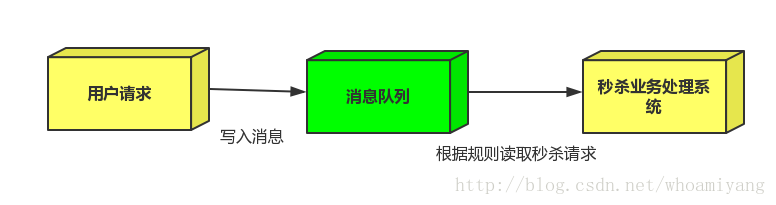
1.用户的请求,服务器收到之后,首先写入消息队列,加入消息队列长度超过最大值,则直接抛弃用户请求或跳转到错误页面.
2.秒杀业务根据消息队列中的请求信息,再做后续处理.
RabbitMQ的集群
集群架构
普通集群(副本集群)
All data/state required for the operation of a RabbitMQ broker is replicated across all nodes. An exception to this are message queues, which by default reside on one node, though they are visible and reachable from all nodes. To replicate queues across nodes in a cluster –摘自官网
默认情况下:RabbitMQ代理操作所需的所有数据/状态都将跨所有节点复制。这方面的一个例外是消息队列,默认情况下,消息队列位于一个节点上,尽管它们可以从所有节点看到和访问
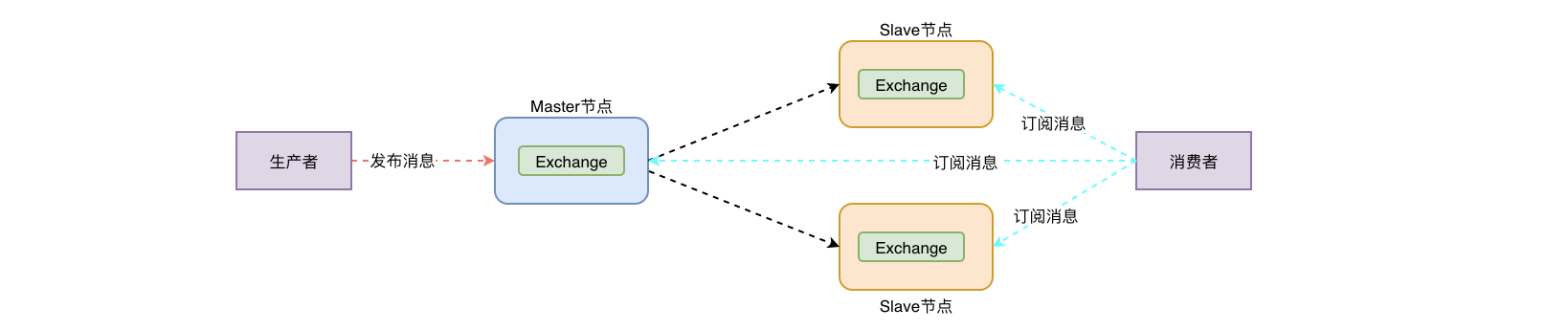
核心解决问题: 当集群中某一时刻master节点宕机,可以对Quene中信息,进行备份
集群搭建
# 0.集群规划 node1: 10.15.0.3 mq1 master 主节点 node2: 10.15.0.4 mq2 repl1 副本节点 node3: 10.15.0.5 mq3 repl2 副本节点 # 1.克隆三台机器主机名和ip映射 vim /etc/hosts加入: 10.15.0.3 mq1 10.15.0.4 mq2 10.15.0.5 mq3 node1: vim /etc/hostname 加入: mq1 node2: vim /etc/hostname 加入: mq2 node3: vim /etc/hostname 加入: mq3 # 2.三个机器安装rabbitmq,并同步cookie文件,在node1上执行: scp /var/lib/rabbitmq/.erlang.cookie root@mq2:/var/lib/rabbitmq/ scp /var/lib/rabbitmq/.erlang.cookie root@mq3:/var/lib/rabbitmq/ # 3.查看cookie是否一致: node1: cat /var/lib/rabbitmq/.erlang.cookie node2: cat /var/lib/rabbitmq/.erlang.cookie node3: cat /var/lib/rabbitmq/.erlang.cookie # 4.后台启动rabbitmq所有节点执行如下命令,启动成功访问管理界面: rabbitmq-server -detached # 5.在node2和node3执行加入集群命令: 1.关闭 rabbitmqctl stop_app 2.加入集群 rabbitmqctl join_cluster rabbit@mq1 3.启动服务 rabbitmqctl start_app # 6.查看集群状态,任意节点执行: rabbitmqctl cluster_status # 7.如果出现如下显示,集群搭建成功: Cluster status of node rabbit@mq3 ... [{nodes,[{disc,[rabbit@mq1,rabbit@mq2,rabbit@mq3]}]}, {running_nodes,[rabbit@mq1,rabbit@mq2,rabbit@mq3]}, {cluster_name,<<"rabbit@mq1">>}, {partitions,[]}, {alarms,[{rabbit@mq1,[]},{rabbit@mq2,[]},{rabbit@mq3,[]}]}] # 8.登录管理界面,展示如下状态:
# 9.测试集群在node1上,创建队列
# 10.查看node2和node3节点: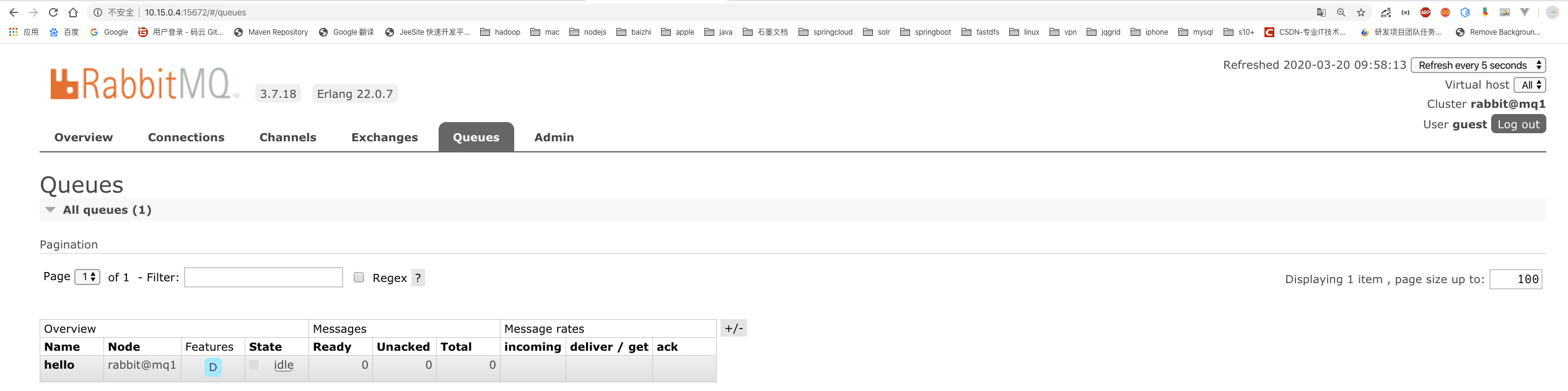
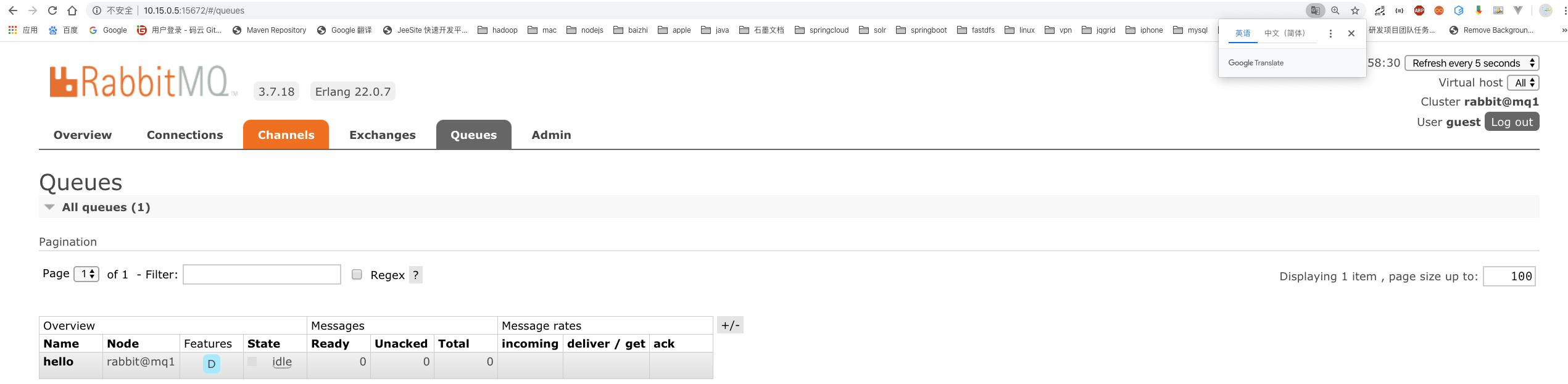
# 11.关闭node1节点,执行如下命令,查看node2和node3: rabbitmqctl stop_app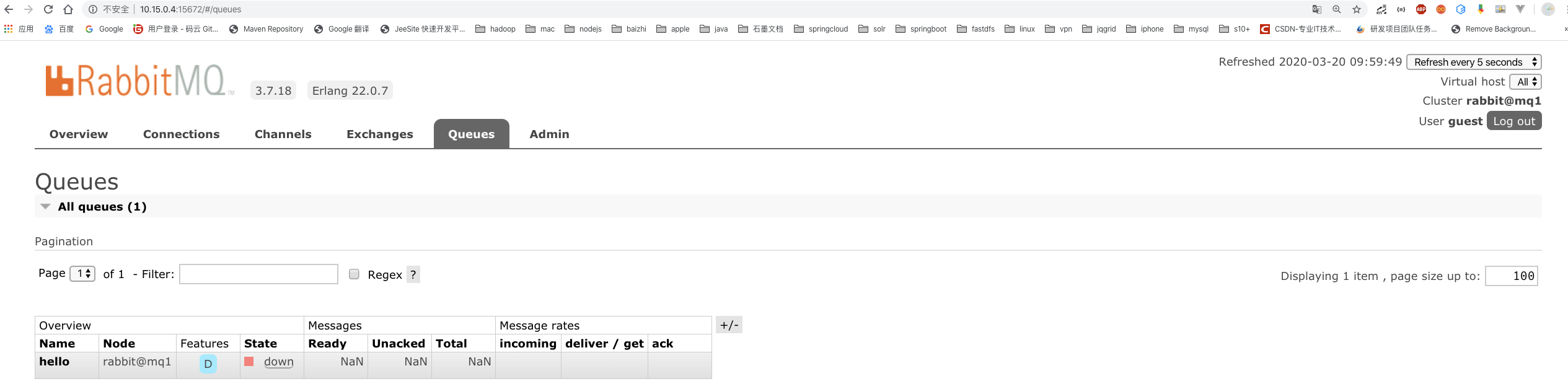
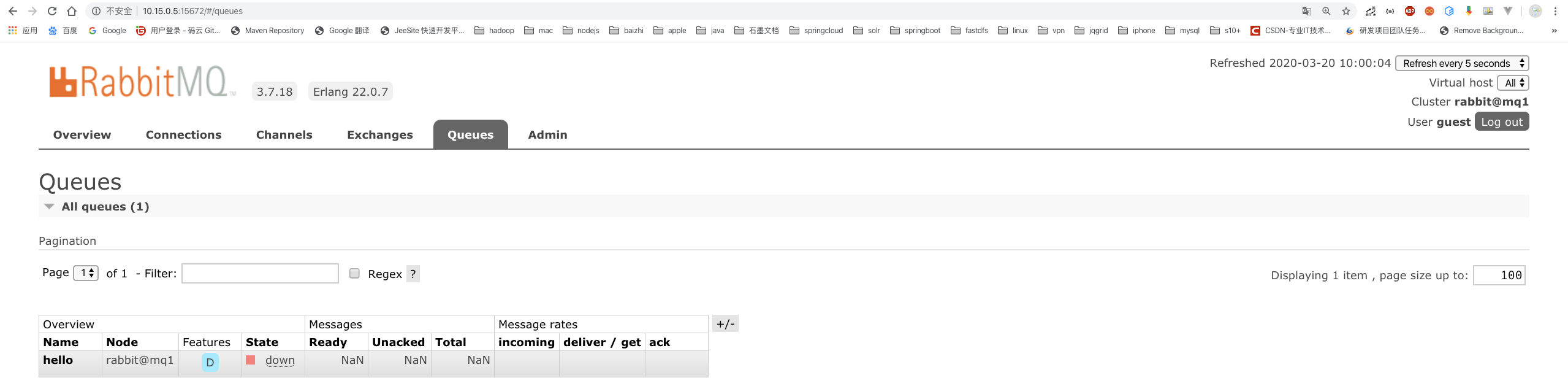
镜像集群
This guide covers mirroring (queue contents replication) of classic queues –摘自官网
By default, contents of a queue within a RabbitMQ cluster are located on a single node (the node on which the queue was declared). This is in contrast to exchanges and bindings, which can always be considered to be on all nodes. Queues can optionally be made mirrored across multiple nodes. –摘自官网
镜像队列机制就是将队列在三个节点之间设置主从关系,消息会在三个节点之间进行自动同步,且如果其中一个节点不可用,并不会导致消息丢失或服务不可用的情况,提升MQ集群的整体高可用性。
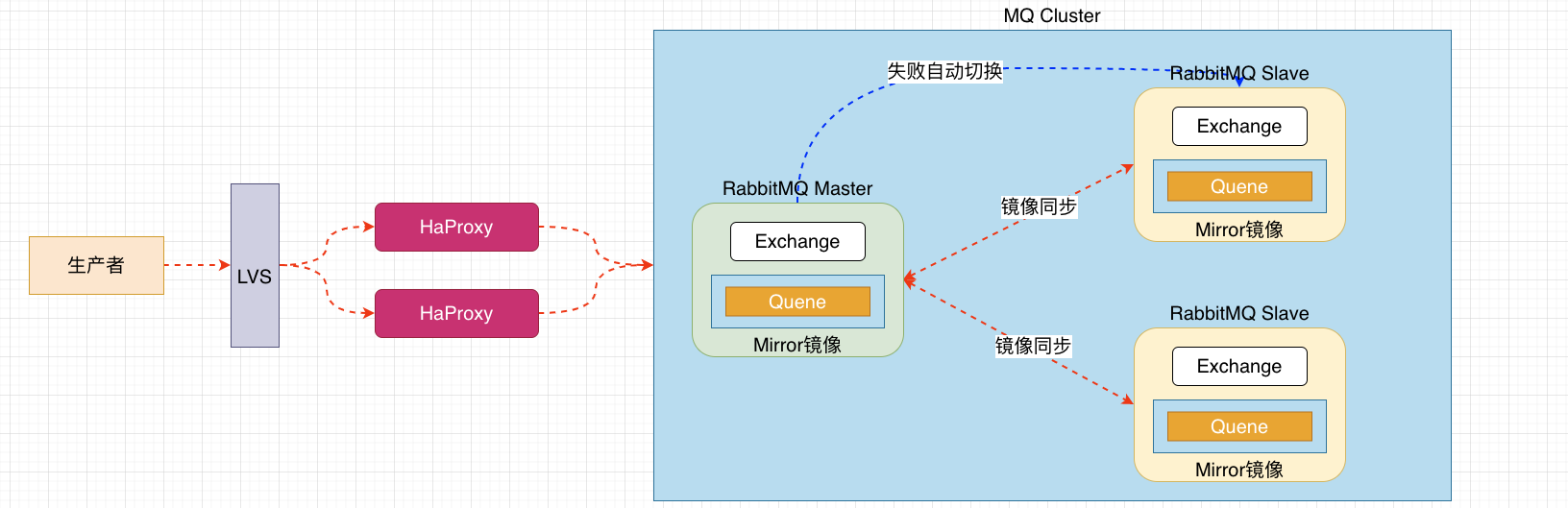
配置集群架构
# 0.策略说明 rabbitmqctl set_policy [-p <vhost>] [--priority <priority>] [--apply-to <apply-to>] <name> <pattern> <definition> -p Vhost: 可选参数,针对指定vhost下的queue进行设置 Name: policy的名称 Pattern: queue的匹配模式(正则表达式) Definition:镜像定义,包括三个部分ha-mode, ha-params, ha-sync-mode ha-mode:指明镜像队列的模式,有效值为 all/exactly/nodes all:表示在集群中所有的节点上进行镜像 exactly:表示在指定个数的节点上进行镜像,节点的个数由ha-params指定 nodes:表示在指定的节点上进行镜像,节点名称通过ha-params指定 ha-params:ha-mode模式需要用到的参数 ha-sync-mode:进行队列中消息的同步方式,有效值为automatic和manual priority:可选参数,policy的优先级 # 1.查看当前策略 rabbitmqctl list_policies # 2.添加策略 rabbitmqctl set_policy ha-all '^hello' '{"ha-mode":"all","ha-sync-mode":"automatic"}' 说明:策略正则表达式为 “^” 表示所有匹配所有队列名称 ^hello:匹配hello开头队列 # 3.删除策略 rabbitmqctl clear_policy ha-all # 4.测试集群



- Post link: http://sovzn.github.io/2023/08/12/RabbitMQ%E9%9B%86%E7%BE%A4/
- Copyright Notice: All articles in this blog are licensed under unless otherwise stated.
若没有本文 Issue,您可以使用 Comment 模版新建。
GitHub Issues